
自社の”独自知”をAIに渡すための実践知
JDMCコミュニティ「データマネジメント座談会」主催のオープン勉強会 #4が、2026年3月16日にオンラインで開催された。データ活用一筋19年のキャリアを持ち、2025年2月に株式会社データミネーションパートナーズを設立した半田裕明氏が登壇。「AI-Readyデータ化の障壁と、グラフDBが導く構造的突破口」と題した講演では、AIへの過度な期待と現場の実態のギャップを整理しながら、2つのライブデモを交えて企業独自データをAIに理解させる実践的な方法論を示した。
「同質化」圧力が、独自データの価値を問い直す
生成AIの普及が企業に突きつけているのは、「AIを使うか否か」ではなく、「AIが同じ答えを返してくる時代に、どう差異化するか」という問いだ。
半田氏はこの状況を「同質化」と表現した。AIのレコメンドが均質化すると、差異化できない企業は埋没する。その一方で、属人化した職人技や現場ノウハウをAIに渡すことができれば、組織全体に一気にスケールさせるチャンスにもなる。鍵になるのは「自社だけが保有する独自データをAI-Ready化すること」だという視点が、講演全体の前提として置かれた。
では、そのAI-Ready化を阻む壁はどこにあるのか。半田氏は「組織の壁」「データ構造化の壁」「データ構造をAIに理解させる壁」の3層構造を示した。組織の壁は切実ではあるが一朝一夕に解決できないとして、今回は後の2つの壁に焦点を絞った。
AI-Readyデータ化は「LV3」が目標、現実はLV1から始まる
「AI-Readyデータ化」とは、半田氏の定義では「組織内に散在する独自知を、AIが即座に理解・学習できる形式へ変換するプロセス」を指す。そのレベル感を可視化したのがLV1〜LV3のフレームワークだ。
LV1は生データで、JSONやXML、ExcelやPDF、音声・画像など業種ごとに多様な形態をとる。この状態でAIに放り込んでも精度は出ない。LV2では構造化データとしてRDBに格納し、メタデータを付加した段階。LV3はさらに意味定義が整い、データカタログやナレッジ辞書が充実した「AI最適化」状態を指す。
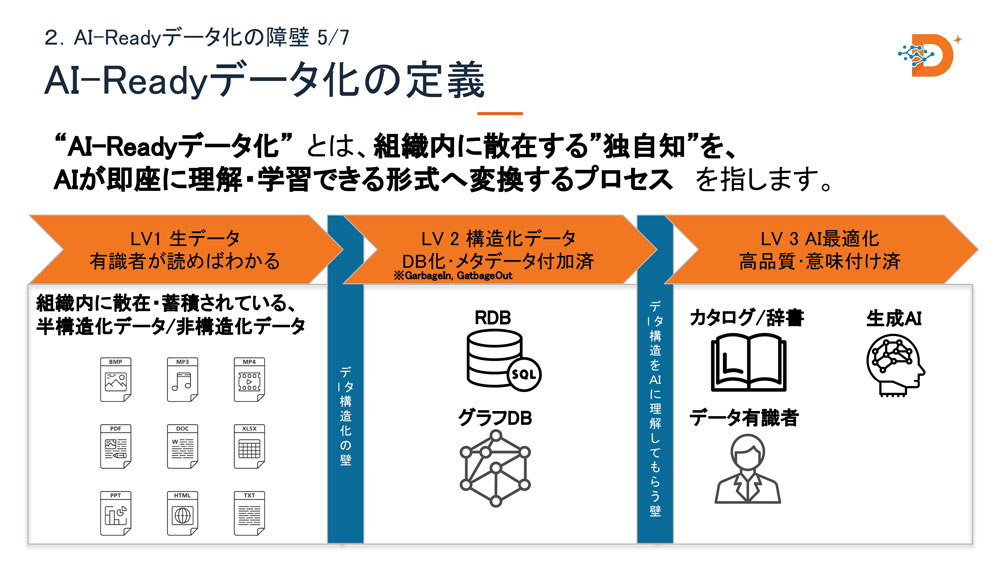
多くの企業が直面している現実はLV1からLV2への壁だ。問題はデータの中身ではなく、AIに「これは何のデータか」という意味を伝えられていない点にある。
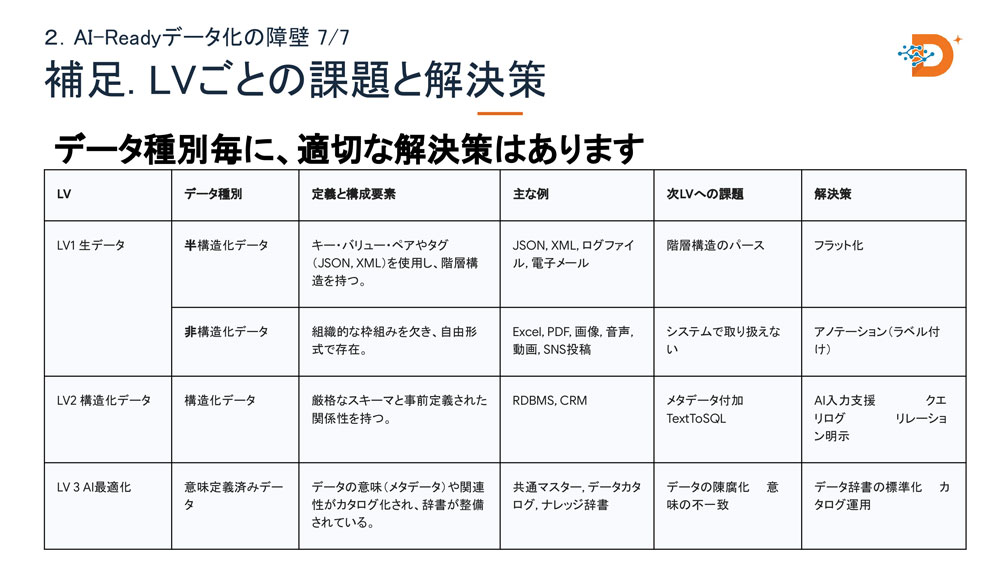
デモ①:ExcelのテーブルDefinitionがTextToSQLを変える
最初のデモは、業務システムのRDBから「地域別・学校別の教科ごとの平均点」を出すSQLをAIに生成させるシナリオだった。現場でよく行われているのは、テーブル作成SQL(DDL)を生成AIに渡す方法だ。しかしDDLには日本語の意味情報が含まれないことが多く、テーブル名だけを見てもAIが正しいテーブルを選べない。結果として、9テーブル中5つを結合すれば答えに近づける設計にもかかわらず、誤ったテーブルを参照した不正確なSQLが返ってくる。
ここで半田氏が持ち込んだのが、Excelのテーブル定義書だ。テーブルの論理名、カラムの説明情報、テーブル間の関係線といったメタデータは、多くの場合SIerが作成した定義書の中にしか存在していない。この情報をAIに連携する際に重要なのが「人間による正しい対応付けの指定」だと半田氏は強調する。
「ExcelファイルをそのままAIに放り込んでも、構造を誤解してしまうことがある。UIで正しい対応付けを指示することで、はじめて精度の高い構造化データとして認識させられる」(半田氏)
この仕組みを実装したのが、半田氏が開発したデータモデリングツール「Mode-ai」だ。テーブル定義書を読み込み、独自のAI-Readyデータ言語「AIR-DML™」でコード化することで、生成AIがテーブル構造とリレーションを正確に把握できるようになる。同ツールはnpmで公開されており、リリース後1週間で1,916ダ ウンロードを達成した。
デモ②:グラフRAGで「障害の影響範囲」を全体から辿る
2つ目のデモは、製造業のITシステムを想定した影響範囲分析だ。「あるサーバーが停止したとき、どの業務部門への影響を通知する必要があるか」という質問に対し、グラフDB(グラフデータベース)と生成AIを組み合わせたGraphRAGが回答を返す仕組みを披露した。
グラフDBには、会社・部署・業務プロセス・ITシステム・処理テーブル・サーバー・法規制の関係を24ノードで定義してある。RDBに格納されたその企業固有のナレッジテーブルと連携させると、生成AIは「グラフ構造から全体を俯瞰してどこを調べるべきかを判断し、ピンポイントで独自データを検索し、不足分があれば一般知識を補完する」という3ステップで回答する。
RDBでは多段のJOINが必要になる複雑な関係性も、グラフDBなら「たどってたどって全体を把握する」経路探索の形で処理できる。半田氏は「10万リレーションのスケールになると人間の目では追えなくなる。グラフDBとグラフRAGを組み合わせることで、そのスケールに耐えうる仕組みが作れる」と説明した。
なぜいまGraphRAGなのか:「意味」と「繋がり」の時代へ
データ活用の技術史を振り返ると、2000年代の構造化データ(DB)の時代、2010年代のビッグデータの時代、2023〜24年の初期RAGの時代を経て、現在はGraphRAGの時代に入っていると半田氏は整理する。
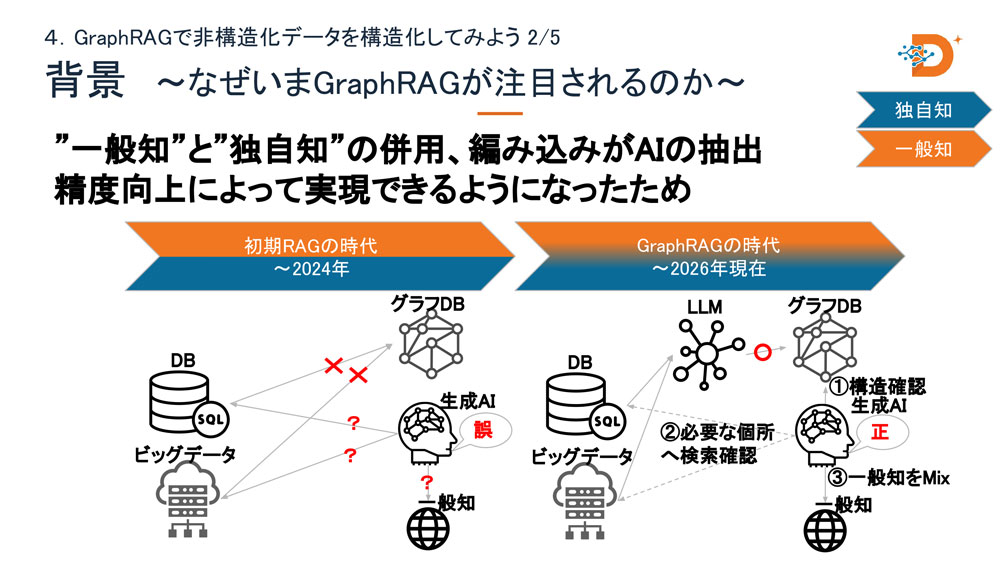
初期RAGの弱点は、文書をチャンク(断片)に分割して検索する仕組みゆえ、大量データの全体像を参照した回答が苦手だった点にある。GraphRAGはナレッジグラフを介してグローバル検索をかけることで、この弱点を補う。技術的には既存のデータをグラフDBにインポートする際にLLMを中継役として使えるようになったことが、実用化を一歩前に進めた。
「以前は技術としてグラフDBはあったのに、独自データをうまく入れる方法が確立されていなかった。それが今はできるようになってきた」(半田氏)
データ設計とスキルの現実的な議論
質疑では「グラフDB構築に必要なスキルは何か」という問いが複数寄せられた。半田氏の回答は明確だった。「情報システム部門のITリテラシーを持った人材は必須。ビジネス部門がレイヤー構造のデザインを描けても、非構造化データをAIが理解できる形でグラフDBに投入するロジックは、技術的な知見がなければ補えない」。
適性のある人材像として挙げたのが、データモデリングの経験者だ。「意味構造を読み解くことに躊躇がない人。Web系エンジニアは処理フローの設計が得意でも、データの”意味”に踏み込む習慣がない場合が多い。データの意味に興味がある人が向いている」。
また「スキーマレスなグラフDBでも、闇雲にリレーションを増やすべきではないか」という質問に対しては「あらかじめデータ設計を行うべき」と答えた。BMW事例を引き合いに、ノード数が増えるとリレーションの整合性を統計的な視点で管理する必要が出てくるため、設計なきグラフDBは維持困難になると指摘した。
開催概要
- イベント名:JDMCコミュニティ「データマネジメント座談会」主催 オープン勉強会 #4(https://jdmc.connpass.com/event/386505/)
- 日時:2026年3月16日
- 形式:オンライン(Zoom)
- 登壇者:株式会社データミネーションパートナーズ 代表取締役 半田裕明氏
- 進行:コミュニティリーダー 加藤俊氏、岩渕史彦氏
デモで使用したMode-aiは無償提供されており(https://mode-ai.io/)、講演資料もJDMCコミュニティで公開予定。