
(MDMとデータガバナンス研究会リーダー・水谷 哲)
 2021年12月16日に開催されたMDMデータガバナンス研究会では、シマントが提供するセマンティックDWHソリューション「SImount DWH」が紹介された。SImount DWHは、正規系や非正規系を問わずフォーマットがバラバラのデータを格納でき、データ整形加工ツールや統合データベースを作成していくための名寄せ機能を備えたDBMSである。SImount DWHを採用することで、どんなことができ、どんな効果が得られるのか。そしてどのような仕組で実現しているのか。シマントの代表取締役の和田怜氏とCTOの渡邉繁樹氏がSImount DWHの仕組み、機能、特徴、効果などについて解説した。
2021年12月16日に開催されたMDMデータガバナンス研究会では、シマントが提供するセマンティックDWHソリューション「SImount DWH」が紹介された。SImount DWHは、正規系や非正規系を問わずフォーマットがバラバラのデータを格納でき、データ整形加工ツールや統合データベースを作成していくための名寄せ機能を備えたDBMSである。SImount DWHを採用することで、どんなことができ、どんな効果が得られるのか。そしてどのような仕組で実現しているのか。シマントの代表取締役の和田怜氏とCTOの渡邉繁樹氏がSImount DWHの仕組み、機能、特徴、効果などについて解説した。
■起業のきっかけは、前職場でデータ活用に苦労していたこと
シマントは2014年8月に設立された社内に存在する全てのデータを統合・名寄せするDBMS「SImount DWH」を提供するITベンチャーである。最大の特徴はマルチバリューデータベースシステム「SMV(SImount Smart multi-value system)」を採用していること。なぜ、このような技術を使ったソリューションを提供する企業を起業したのか。また「SImount DWH」とはどんなソリューションなのか。和田氏の発表を以下に紹介する。
 起業のきっかけは、前職のみずほ銀行で業務システムがサイロ化していることから、企画業務が進まないという経験をしたことです。
起業のきっかけは、前職のみずほ銀行で業務システムがサイロ化していることから、企画業務が進まないという経験をしたことです。
銀行では流動性預金、定期性預金、内為、営業店業務、融資、外為、グループ会社連携など、さまざまな業務システムが稼働しています。また、部署によっては業務システムのデータを加工してエクセル管理しているものもあります。私は、それら部署ごとに管理している業務データをもらってきて、上司に報告するための集計作業を担当していました。ここで2つ困ったことがありました。
1つはマスターデータが業務システムごとにサイロ化して不整合だったこと。
もう1つがトランザクションデータの金額単位・入力フォーマットが不整合だったことです。
例えば金額の単位が1000円単位のデータもあれば100円単位のデータがあったり、USドル建て、円建て、ユーロ建てなど為替の違いもあったりとデータの粒度がバラバラなため、データの整形や加工作業で手一杯となり、分析や企画などの本来業務に集中して取り組めませんでした。
そんなとき、出会ったのが当社のCTOであり、マルチバリューデータベースの生みの親、Dick Pick氏と共に、マルチバリューデータベースを開発した経験を持つ渡邉繁樹でした。マルチバリューデータベースの話を聞き、この技術を使えば、先のような課題が解決できると考え、起業することにしました。
■MDMが進まない理由
一般的に理想とするマスタデータマネジメント(MDM)とは、各業務システムをすべて網羅するマスタデータマネジメントシステムによりきちんと管理されている状態を指します。ですが、現実はそういう状況にはなく、次のような問題を抱えています。1つ目の問題が全社的に強い権限を持つ、データオーナーがいないこと。最近では、CIOのポジションやデータを利活用するセクションを立ち上げたり企業も増えていますが、業務システムを持っているデータオーナーつまり現場に対してはどうしても遠慮がちになってしまったり、実データを見る機会がないため空中戦の議論になりがちだったりします。2つ目の問題は個別管理するExcelマスタの存在です。業務システムとは別に各現場で個別にExcelにより管理されているデータが存在する場合があり、また各現場の特定の人に全社的な視点はありません。このため、全社のデータを集めて統一の目線で管理しようとすると、辻褄が合わなくなることがあります。3つ目の問題は、そういった個別の問題を全社的に解決しようとすると、マスターデータの作り直しによる開発コストと期間がかかること。この3つの問題によりMDMが進まないのではないかと考えています。
■SImount DWHはどんな課題を解決するのか
では私たちのソリューションを用いると、どういうことが実現できるのか。大手信託銀行の事例をご紹介します。同社では企画セクションがAIを日常的に活用するためのプロジェクトを立ち上げました。ですが、実際にプロジェクトが始まり、AIを活用しようとするとデータ連携がされておらず、使えるデジタルデータが存在せず行き詰まったのです。
具体的には、不動産システム、CRM系の各事業部共通で使うシステム、証券代行システム、年金システムといった部門システムが多数存在し、例えば不動産だと顧客番号、各事業共通システムはRM番号というように、顧客に関する主キーもバラバラでした。もちろん、網羅的なMDMは入っていません。
この問題に対し、私たちはSImount DWHを使って解決を図りました。
私たちのソリューションで使っているのはマルチバリューデータベース(以下、マルチデータDB)。行・列方向に自由に複数のデータを拡張可能なデータベースです。完全可変長でデータ保持が可能なので、システム運用開始後のカラム追加も可能で、軽い・早い・楽という特徴を持っています。
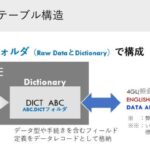
マルチバリューDBはテーブル構造に特徴があります。1つのテーブルをRaw DataとDictionaryという2つのフォルダで構成していること。Raw Dataはデータをそのまま(型なし)で格納し、Dictionaryでデータ型や手続きを含むフィールド定義を格納します。データを加工する場合は、Dictionaryを通してRaw Dataにアクセスし、結果を返します。DictionaryはRaw Dataに対して複数持つことができ、またDictionaryテーブルを追加することも可能です。
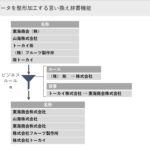
このマルチバリューの機能に付随して、SImount DWHの3つのユニークな機能を有しています。第一はビジネスルール管理。SImount DWHはビジネスルールを通して、データのやり取りを管理します。例えばAとDという2つのテーブルをつなぐ(寄せる)キーがAのデータからだけは生成できない場合、ADというビジネスルールに従い、ニカワとなるキー(SImountではアソートと呼ばれる)を高速生成し、AテーブルとDテーブルを統合し、DB化することができます。テーブルはいくつも掛け合わせることができ、ビジネスルールも複数保持できます。またビジネスルールとビジネスルールを掛け合わせて、複合的なビジネスルールを作ることもできます。ビジネスルールはDictionaryを介すことで、名寄せだけではなく、検索や集計も可能になります。

具体的にどんなことが可能になるのか、ご説明しましょう。事前に結合用のすべての値を含んだマスタは不要です。テーブルAのキー「取引店(A列)と顧客番号(B列)」とテーブルBのキー「取引店(C列)と顧客番号(D列)というように、位置が異なる列を結合用キーとして定義します。結合用キーのビジネスルールに定義に従い、キーの対応表が自動作成されます。新たに生成された、統合IDという内部IDをベースにAとBを掛け合わせたモノが自動的に生成され、マスタが結合されます。また対応関係を表すデータ列をアソートキーとして同期指定することにより、それらを同一と判断し、これによりさまざまなキー項目で1つに統合したテーブルを構築することが可能になります。このような仕組みを使うことで、違う項目でも同一の集約キーとして結合可能になり、実質的な名寄せの対応表マスタとして機能することで、名寄せが実現するのです。

 またデータ整形加工する際の言い換え辞書機能も提供しています。例えば元のデータが東海商会(株)やトーカイ(株)と表記が揺れていたとしても、(株)を株式会社に置き換えるというルールを定義し、また言い換え辞書でカタカナ表記のトーカイを東海商会株式会社という漢字に置き換えるというビジネスロジックを通すことで、キレイな形に整形できます。
またデータ整形加工する際の言い換え辞書機能も提供しています。例えば元のデータが東海商会(株)やトーカイ(株)と表記が揺れていたとしても、(株)を株式会社に置き換えるというルールを定義し、また言い換え辞書でカタカナ表記のトーカイを東海商会株式会社という漢字に置き換えるというビジネスロジックを通すことで、キレイな形に整形できます。
さらに業務部門で独自に管理されているExcelファイルもデータとして取り扱うことができます。例えば海外拠点ごとに顧客番号の表記がバラバラであっても、SImount DWHで読み替え、元データに対してきれいな形にしてデータとして吐き出すことが可能になっています。
さらにSImount DWHはあいまい検索・ファジー検索にも対応しています。例えばRM番号が抜けている不完全な入力データでも、顧客名で名寄せをしたり、正確な会社名でないデータに対しては、あいまい検索により類似率の高いモノを候補として提示し、人が目視して欠損値を埋めたりできるなどです。
このようにSImount DWHは、バラバラのデータを一箇所に集める統合だけではなく、データを活用できるよう整形するための機能を提供します。SImount DWHを活用した名寄せ・マスターデータ統合業務手順の基本フローチャートは次の図のようになります。
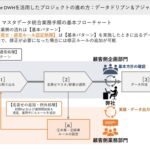
事例では、元データを取り込み、名寄せのパターン・ロジックを顧客側の企画部門と弊社エンジニアと打ち合わせして、まず叩き台となるデータを作成しました。出力されたデータは業務部門がチェックします。要望に応じてルールを追加し、さらにデータを取り込み、名寄せマスタ/辞書の定義をする。このサイクルを何度も繰り返し回しながら正解に近づけるアジャイルな方法でデータマネジメントを進め、運用しながら活用できる正解のデータへと近づけていきました。
冒頭の信託銀行の事例では1年掛けて、SImount DWH内部で管理する結合IDで仮想的な統合管理を実現。全業務システムを網羅したマスターデータマネジメントを進め、現在はAIやクラウド系のサービスとの連携を実現しています。
■一般的なデータ標準化技術との違い
ではSImount DWHは一般的なデータ標準化技術と何が違うのか。最大の違いは、バラバラな業務データを何の処理もせずに、そのままSImount DWHに送信するだけで、他のシステムにつなげていくことができることです。一般的には、DWHに収納する前に整形加工および正規化をする必要があり、最近ではData Lake、ETL、DWHと各工程に分かれた製品が存在していますが、SImount DWHではその工程を全てSImount DWH内部で行います。このため、現場に収納前のデータ加工等の負担をかけることがなく、現場に使いやすいデータマネジメントと言えると思います。データに関するビジネスルールをDWHに溜めながら、小さくスタートし、運用しながら少しずつ改善を図ることができるため、開発コストと期間の適切化・圧縮も実現します。
■マルチバリューデータベースの特徴
ここで一旦、和田氏の発表は終了。リーダーの水谷氏から「マルチバリューについてもう少し詳しい説明がほしい」というリクエストがあった。それにシマントCTOの渡邉氏が答えた。
マルチバリューデータベースの特徴は、Excelをそのまま取り込めることです。Raw Dataは本当にそのままのデータを扱います。読み込み方もさまざまあります。例えば1シート1レコードとして読み込むこともできれば、1行を1レコードとして読み込むこともできます。また1行を1レコードとして読込んだ場合に当社のSMV SImount DWHシステムでは順番号のキーが無くともn行目はn番目のレコードという形で読み込むことができ且つ高速なダイレクトアクセスも可能です(これは当社の特許技術です)。
Excelのような、式を入れると値が出るといったフィールド(仮想フィールドと呼称)も生成できます。一般には(株)を株式会社として扱いたい場合は、(株)を株式会社という物理データに変更する必要があります。SImount DWHだと、 (株)を株式会社として扱いたい場合は、Dictionaryに「(株)を株式会社として表現する」仮想フィールドを定義(例えばこの場合の定義関数は、CHANGE(x,”(株)”,”株式会社”))することで、あたかもデータとして~株式会社という文字列が入っているように扱えるのです。
加えてRDBMSにおけるJOIN処理のような結果を導出するフィールドも定義できます。例えばRaw Dataに入っている「3」というデータをキーとして、マスターを通して名前を持ってくるようなことを一つの「仮想フィールド」として定義することもできます。この場合もRaw Dataの「3」はそのままで、物理的にはなんら加工は加わりません。ビジネスルールを仮想フィールドとして定義することでそういう変換が容易にできるのです。ビジネスルールもテーブル上のデータとして管理できるため、メタデータ管理も一緒に可能というわけです。尚、元データを物理的に変更することが無いため、このような定義は実システムが稼働中であっても可能であり、必要であれば即時実行することができます。またダイナミックアレイ構造による完全可変長レコードの性質上、実データフィールドの新規定義も仮想フィールド同様にシステム稼働中でも容易に行うことができます。
また、通常のデータ統合の場合は、プログラム内にルールが埋め込まれれてしまうことを避けることはできません。ルールを変更する場合には複雑なプログラムを読み解いてゆく必要があります。我々が提供するSImountDWHでマネジメントすれば、ビジネスルールをプログラムではなくディクショナリに書くことで変更つまりメンテナンスを格段に容易にし且つ統一管理することができます。
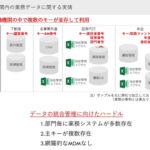
ビジネスルールには、部分部分で書いていけるというメリットもあります。例えば、あるキーがあり、AというデータとXというデータをつなごうとすると、そこに何段階もルールを設ける必要があったりします。そういったものを一気に書くこともできますが、部分部分で書いていくこともできます。
たとえば、とあるデータでは「○オンスで△ドル」というマスタがあったとします。これを「○グラムで△円」というマスタとして参照したい場合、オンスをグラム換算する仮想フィールドと、照会時の為替にてドルを円換算する仮想フィールドをそれぞれ独立して作っておけば可能です。
ビジネスルール1を実現する仮想フィールドを作成し、ビジネスルール2、ビジネスルール3でまた別の仮想フィールドをそれぞれ作る。仮想フィールド以外に実フィールドも使い、これらの4つのフィールドをマージしてビジネスルール5をつくることもできます。お客様の実際の業務でも、基本ルール組み合わせて応用ルールを作るようなヒエラルキー構造があります。つまり現実の業務と同じルールを同じ構造で、Dictionaryにて表せるようになっているのです。これもSImount DWHの特徴です。
■レコードは区切りマークを使用し、詰めて格納
水谷 マルチバリューを支える「区切り」の持ち方について教えてください。
渡邉 高級言語がFORTRANやCOBOLやALGOLという言語しかなかった時代に、高級言語上にて完全可変長データを実現する為にDick Pickが考え出したのが「ダイナミックアレイ」と呼ぶデータ構造で、現在では半構造といわれるものです。完全可変長を実現する方法には半構造以外にポインターを使用した木構造も考えられるのですが、若きPickは高速なトランザクション処理やそれに伴い必須である動的GC(ギャベッジコレクション)を可能とするハッシュファイルの実現を考慮したうえで敢えて半構造を基としたダイナミックアレイを考案したものと思います。マルチバリューのレコードはこのダイナミックアレイ構造で成り立っています。例として図の上半分が示しているものは論理的レコード構造ですが、その物理構造は下半分に示すようなダイナミックアレイ構造として実現されています。実際にSImount DWHで収納されているレコード構造は、物理的に上図論理構造を折り畳むような形で、区切りマークにてヒエラルキーを構成します。
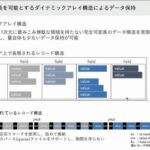
IDとフィールドの間はidマークで区切られ、フィールドとフィールドの間はフィールドマーク、バリューとバリューの間はバリューマークで区切られます。またバリューをサブバリューマークにて区切ることにより3次元構造の配列まで作れます。このようにマークで区切っていくことで、可変長を実現しています。1レコードが1バイトでも、1億バイトでも構造は同じです。
また一般に可変長レコードはトランザクション処理に向いていないといわれます。実際にドキュメント型といわれるデータベースではトランザクション処理は不可としているものがほとんどです。しかしPick系のマルチバリューシステムにおいてはトランザクション処理はRDBMSと同等以上に緻密でかつ断然高速です。RDBMSではトランザクション処理においてレコード長が少し長くなっただけで急に使い物にならなくなったりします。つまり性能のスレッショルドがあります。SImountDWHもレコード長が長いより短い方が性能は良いですが、緩やかにしか性能は落ちていきません。
またドキュメント型の場合、追加してゆくだけでも突然とてつもなく遅くなる事があります。これらは何れもガベージコレクションがトランザクション用に考えられた仕組みになっていないからです。
例えば完全可変長はデータがキッチリと詰まって入っていると調子がよく問題は発生しないのですが、短いレコードが更新時に長くなったときはそのまま元の場所に戻すことができません。それを繰り返していくとテーブル内があちこち穴だらけになり所謂フラグメンテーションが発生します。そうなると性能が落ちる、HDDの容量を食う、という大きな問題が生じます。そこでガベージコレクションを行うのですが、私が知る限り現存する有名なドキュメント型データベースはある閾値を越えたような場合にトリガー的に実行される仕組みになっており、レコード長の長短差が大きい場合にはガベージコレクションが恐ろしく遅くなることが避けられません。そのため、完全可変長と言ってもその製品に最適なレコード長を考えながら使うのが常識となっているのです。
一方、我々のソリューションではガベージコレクションはレコードの出し入れ時に超高速でダイナミックに行うよう考えられており、レコードの長短にかかわらず長さが変化したデータを元の場所に戻すときにはできるだけ詰めて入れるようになっています。例えば今から10年以上前に現SImountのSMVと同等のエンジンを使用し第三者的立場にあるSIerが、当時トランザクション処理で最も速いと言われるRDBMSと比べて、アプリケーション総体で約20倍以上の性能差があり採用されたという実績があります。
水谷 上の図を横に並べていったのが、下の図ということですね。空白のところはNullが入っているという形でしょうか。
渡邉 そうです。最大3次元の配列を1次元のレコードで表したということです。実際にコーディングする際は、この両方の図を適宜イメージして行います。
マルチバリューデータベースは元々、Pick OSと呼ばれるオペレーティングシステムが内包していたデータファイルシステムだったのです。Pick OSは当時のUNIX BSDをも遥かに凌ぐOSであり開発環境として言語体系も内包していました。例えばRDBMSの言語はSQLですがRDBMSの親言語ではありませんし、いわゆる4GL(FORTRANやCやJAVAは3GL)であり複雑なアルゴリズムやトランザクション処理を目的として開発されたものではありません。一方、当社のSMVマルチバリューシステムではPick OS上にあったすべての言語(jclやunixのshellに相当するPROC,copy等基本命令であるTCL,SQLより前に実用化された照会言語ENGLISH,DBMSのレコードを直接READ/WRITEでき複雑なトランザクション処理を高速実行可能な構造化DATA BASIC)が使用でき、これらを適材適所に使用することにより高機能で高速なシステムを作り上げます。実はSImount DWHもSMVから生まれたそういったシステムのひとつなわけです。
水谷 この方式を使うと、Excelでセル結合などを使った表なども、レコードの形にキレイに収めることができるということですね。
渡邉 なぜ、1行1レコードとしているかというと、Excelは1つのセルの中で改行して複数のデータを入れたりしますよね。それを丸ごと一つのバリューとして実現したかったのです。3次元と2次元を使い分けるのは非常に難しいので、できれば2次元だけで表現したい。1行を1レコードにしておけば、改行されたデータをバリューとして分けることができます。またExcelのカラム内の句読点でバリューに分けることもできます。そうすると検索するときに非常に都合が良かったりするんです。
水谷 文がいくつか書いてあったときに、それぞれを独立したデータとして扱えるということですね。
渡邉 そういうことができます。
■SImount DWHはExcel文化と共存できる
水谷 和田社長もおっしゃいましたが、これからもExcelは消えないと思われます。After ExcelではなくWith Excelにおいて、SImount DWHは非常に有効なソリューションと言うことでしょうか。
渡邉 Excelは文化としては高すぎますからね。高すぎるつまり複合的がゆえに、基礎的な技術だけでは納めきれません。つまり正規化など1つのルールに納まりません。もちろんマルチバリューでも限界はありますが、データサイエンスを活用するギリギリの折衷案だと思います。例えばリレーショナル・モデルの本質は集合理論であり述語論理であって物理位置を考慮しないというか考慮しなくともいいように徹底してコッドは考えたわけです。一方Pickは「RDBは数学の世界だが、Pickは実世界なんだ」と私に諭すかのように何度も話してくれました。当然ですが実世界は位置関係につよく依存しています。「その位置関係がそのモノにとって本質的(生来内包している)なものであれば、それらを写像(モデル化)するデータベースも位置を内包することが自然である」とは35年以上前に来日した時にPickが話した一節でもあります。これについては深遠な議論がのぞまれるのですが、今回は長くなるので止めます。私はマルチバリューの本質は実はここにあると考えています。
水谷 SImount DWHは多くの企業で活用が進みそうですね。
渡邉 完璧なルールをお客さまが自分で考え出すことができれば、我々のようなツールは必要ありません。ですが、そういう企業はほとんどありません。例えスーパーマンがいたとしても、個別部署の人たちの意見を聞きながらつなぎ合わせていかなければいけません。お客さま自身がつかんでいないルールを、一緒に探り出していく。そういうやり方で、少しずつ次の段階に進んでいくことでマスターデータ統合は実現します。重要なのは要件定義、要件を開発するという考え方です。それをふまえて開発したのがこのツールです。
和田 興味があればぜひ、一度、お声がけください。
さまざまなデータの連携を可能にし、Excel文化とも共存できるSImount DWH。データ活用に課題を感じている企業にとって、非常に有効なソリューションになりそうだ。
<関連ページ>
MDMとデータガバナンス研究会について
https://japan-dmc.org/?p=13935
MDMとデータガバナンス研究会レポート一覧
https://japan-dmc.org/?cat=60