
JDMC会員による「リレーコラム」。
メンバーの皆さんそれぞれの経験・知見・想いをリレー形式でつなげていきます。
今回、バトンを受け取ったのは、データブリックス・ジャパン株式会社・弥生 隆明さんです。
こんにちは、データブリックス・ジャパン株式会社の弥生隆明です。データブリックスは、レイクハウスを基盤としたデータインテリジェンスプラットフォームを提供し、組織全体でのデータとAI活用を促進します。統合されたオープン環境で、データ処理から生成AIまで、あらゆるデータジャーニーをシンプルに実現します。
現在、私は生成AIやデータエンジニアリングを専門としたエンジニアとして日々お客様をサポートしています。このコラムでは自らの経験を踏まえ、AI時代におけるデータマネジメントのあり方を考察したいと思います。
●「AI Ready」という言葉の一人歩き
昨今、生成AIを企業活動に取り入れようとする動きが活発になっており、多くの企業がAI活用に向けたデータ基盤構築に取り組んでいます。しかし、データを集めるだけではAI活用は成功しません。
昨今、「AI Ready」という言葉が企業のデータ戦略において頻繁に用いられています。しかし、AI Readyの解釈はさまざまであり、データ基盤の整備という技術的な側面に焦点が当たりがちです。
米国の調査機関RAND Corporationが2024年に行った調査によると、AIプロジェクトの失敗率は80%に達し、これは通常のITプロジェクトの失敗率のほぼ2倍に相当します。また、MITの最新調査では、企業による生成AI導入プロジェクトの95%が損益に測定可能な影響を与えていないことが明らかになっています。
AI導入がうまくいかない、ビジネス上の効果を発揮しない──その要因の一つは、AI Readyの本質的な意味の取り違えにあるのではないでしょうか。重要なのは「どのビジネス課題を解決するか」であり、そのために「どのようなデータが、どのような品質で必要か」を定義することです。例えば、顧客サポートの自動化を目指すなら、過去の問い合わせデータの品質と網羅性が鍵になります。結局のところAIありきではなく、課題起点で考える必要があるのです。 では、この課題起点のアプローチを実現するためには、データマネジメントをどう再定義すべきでしょうか。
●リネージとコンテキストの管理 AIの「透明性確保」に必要な新たなデータガバナンス
ビジネス課題を解決するAIを構築するには、従来のデータガバナンスでは不十分です。従来のデータガバナンスは、データの所在管理、アクセス制御、コンプライアンス対応が中心でした。しかし、AI時代においては、これらに加えて「データのリネージ(系譜)」と「利用コンテキスト」の管理が不可欠になっています。
なぜこれらが重要なのか。まず「データのリネージ」とは、データがどこから生まれ、どのような変換・加工・統合を経て、最終的にどこで使われているかという、データのライフサイクル全体を追跡することを指します。例えば、AIモデルが不適切な予測をした場合、その原因を特定するには、学習データが複数のソースシステムからどう抽出され、どのような前処理やクレンジングを経て、どのテーブルに格納されたかを遡る必要があります。
データのリネージが可視化されていないと、問題の根本原因を特定することができず、AIの信頼性を担保できません。特に金融や医療といった規制の厳しい業界では、AIの判断プロセスの透明性確保が法的要件となりつつあり、データのリネージ管理は必須となっています。
一方、「利用コンテキスト」の管理とは、そのデータが「どのような目的で収集され」「どのような用途で使われることが想定され」「どのような制約があるか」を明確にすることを指します。
例えば、マーケティング目的で収集された顧客データを、本人の同意なく与信審査のAIに使用することは倫理的にも法的にも問題があります。同じデータでも、利用される文脈によって適切性が変わるのです。このため、データカタログには技術的なメタデータだけでなく、収集目的、利用許可範囲、保持期間といったビジネスコンテキストの情報も含める必要があります。 さらに、課題解決の観点からは、データの「鮮度」という概念も重要性を増しています。バッチ処理で日次更新されるデータで十分だった時代から、リアルタイムに近いデータ更新が求められる場面が増えています。需要予測やパーソナライゼーションといったユースケースでは、データの時間的な品質が直接的にビジネス成果に影響します。つまり、ガバナンスの対象は「静的なデータ資産」から「動的なデータフロー」へと拡張されているのです。
●ガバナンス範囲の拡張に従って、データ品質の指標も進化する
ガバナンスの範囲が拡張されるということは、当然、データ品質の評価軸も変化することを意味します。従来の完全性、一貫性、正確性に加えて、AI活用を前提とすると「代表性」と「公平性」という観点が加わります。
この変化は、冒頭で述べた「課題起点」の考え方と密接に関係しています。例えば、営業支援AIを構築する際、過去の成約データが特定の顧客層や地域に偏っていれば、AIの推薦も同様に偏ります。データが統計的に十分な量であっても、ビジネス全体を代表していなければ、AIの判断は現実と乖離し、解決すべき課題の解決には至りません。
また、データに内在するバイアスの検出と是正も重要な品質指標となっています。採用支援AIが特定の属性を持つ候補者を不当に評価してしまうリスクは、データの収集段階から考慮すべき課題です。データ品質の評価は、技術的な正確性だけでなく、倫理的な妥当性も含む多次元的なものへと進化しています。 こうした新しい品質指標を実際に運用するためには、データカタログの役割も変容する必要があります。単なるメタデータの格納庫から、データの品質スコア、利用実績、推奨されるユースケース、さらにはデータの代表性やバイアスに関する情報まで含む、データのショーケースとしての機能が求められています。
●「データとAIの民主化」と「ガバナンス」の両立が求められる
では、データのリネージや利用コンテキストの管理、そして代表性や公平性といった新しい品質指標を、どのように実践に落とし込めばよいのでしょうか。
課題起点でAIを活用するには、現場の人々がデータに容易にアクセスし、自ら仮説を検証できる環境が必要です。つまり、いわゆる「データの民主化」が求められます。しかし、セキュリティやコンプライアンスの観点から、無制限なアクセスは許容できません。この相反する要求をどう両立させるかが、現代のデータマネジメントの大きな課題です。
この課題に対処するには、技術基盤とともに組織的な取り組みが不可欠です。成功している企業の多くは、データオーナー、データスチュワード、データユーザーの役割を明確に定義し、責任の所在を明らかにしています。特に重要なのは、ビジネス部門とIT部門の協働です。ビジネス部門は解決すべき課題とデータの意味や品質要件を定義し、IT部門はそれを技術的に実現する。この両輪がうまく機能して初めて、AIに適したデータマネジメントが可能になります。
●現場担当者が安心してデータを探索、分析できる環境づくり
データアクセスの民主化においては、データの抽象化が有効なアプローチです。生データへの直接アクセスを制限する一方で、集約されたデータや統計情報、あるいは適切にマスキングされたデータを広く提供することで、分析の自由度とセキュリティを両立できます。これにより、現場の担当者は自らの課題に応じてデータを探索し、インサイトを得ることができます。
また、セルフサービス分析の環境を整備することも効果的です。データサイエンティストだけでなく、ビジネスユーザーも自らデータを探索できるような環境は、組織全体のデータリテラシー向上にも寄与します。ただし、その前提として、前述したデータカタログの整備とデータ品質の保証が必要であることは言うまでもありません。
技術面では、データ品質の監視を自動化し、異常を早期に検知する仕組みが不可欠です。AIモデルの精度劣化は、多くの場合、学習データと本番データの分布の乖離に起因します。前述した「代表性」や「鮮度」といった新しい品質指標を継続的にモニタリングすることで、AIシステムの健全性を保ち、ビジネス課題の解決に貢献し続けることができます。 加えて、データの利用履歴とアクセスログを活用した監査の仕組みも重要です。誰が、いつ、どのデータを、何の目的で使用したのかを記録することで、コンプライアンス対応だけでなく、「このデータがどのビジネス課題の解決に貢献したか」という効果測定も可能になります。これにより、データ投資のROIを可視化し、経営層への説明責任を果たすことができるでしょう。
●「AIモデル自体」のガバナンスをどう担保するか?
一方、AIモデル自体のガバナンスも重要な課題です。データへのアクセスを民主化するだけでなく、AIモデルの開発・デプロイ・運用においても、適切なガバナンスが必要になります。具体的には、誰がどのようなモデルを開発し、どのような検証を経て、どこにデプロイされているかを追跡する「AIモデルのリネージ管理」が求められます。これは、データのリネージ管理と同様に、AIシステムの透明性と信頼性を担保する上で欠かせない要素です。なお、Databricksで管理されるデータ、AIモデルのリネージは自動で捕捉され、簡単に関係性を把握できます。
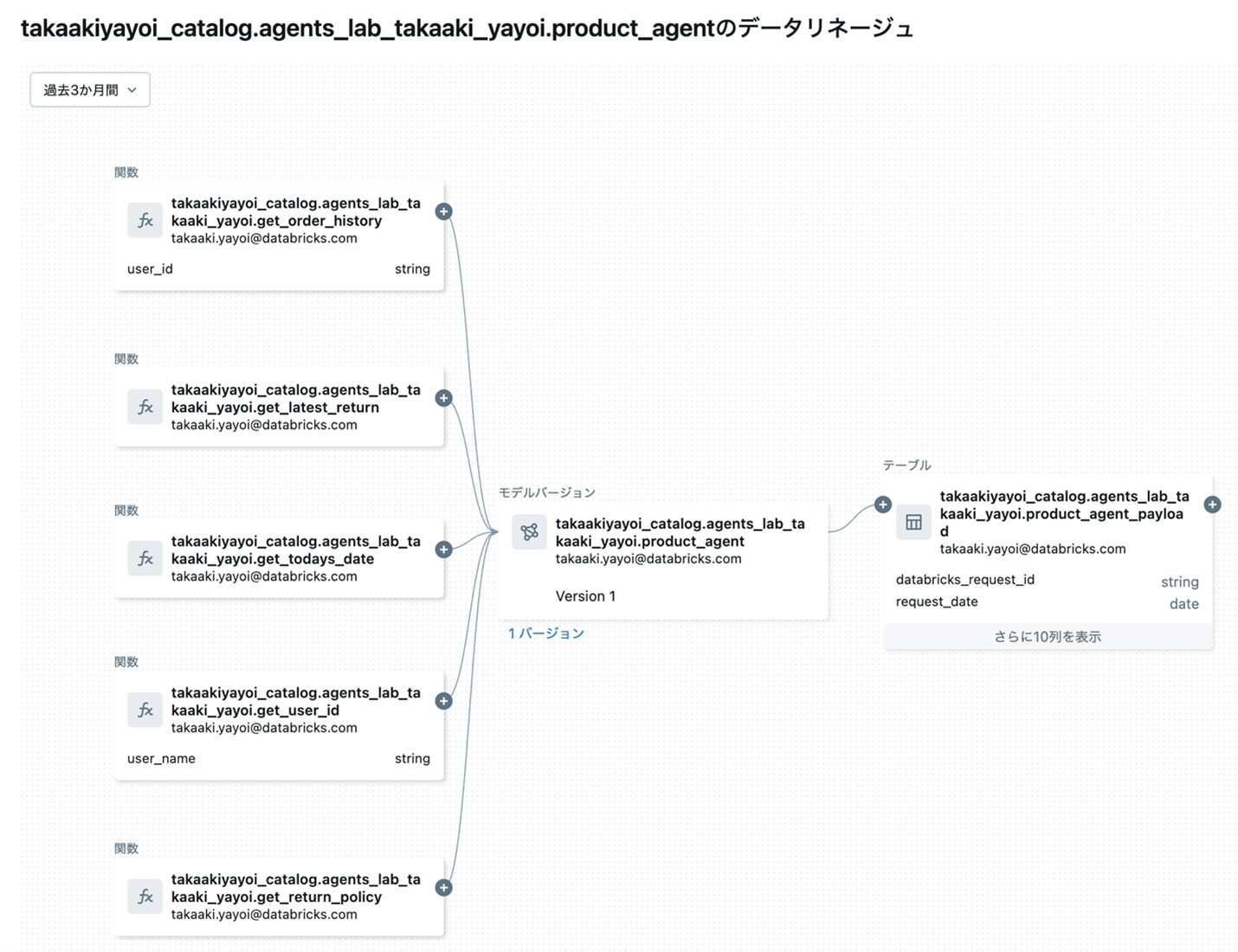
さらに、AIモデルのバージョン管理と実験管理も不可欠です。データサイエンティストが試行錯誤する過程で生まれる無数の実験結果やモデルのバリエーションを適切に管理することで、再現性を確保し、最適なモデルを選択できます。また、本番環境にデプロイされたモデルのパフォーマンスを継続的に監視し、精度劣化が検出された場合には迅速にロールバックや再学習を実行できる仕組みも重要です。
加えて、AIモデルの説明可能性とバイアスの監視も、AIガバナンスの重要な要素です。モデルがどのような特徴量に基づいて判断を下しているのか、特定の属性に対する不当な偏りがないかを定期的に検証することで、AIシステムの公平性と透明性を担保できます。これは単なる技術的な課題ではなく、企業の社会的責任に直結する問題です。 重要なのは、データとAIの両面において、ガバナンスをゲートキーパーではなくイネーブラーとして位置付けることです。規制によってデータ活用やAI開発を制限するのではなく、安全かつ効果的なデータ活用とAI活用を促進する仕組みとしてガバナンスを設計することが、AI時代のデータマネジメントには求められています。これにより、組織全体がビジネス課題の解決に向けてデータとAIを活用できる土壌を整えられるでしょう。
●まとめ:AI時代に求められるデータマネジメントの「本質回帰」
AI時代のデータマネジメントは、決して新しい概念を生み出すものではありません。むしろ、データマネジメントの本質である「正しいデータを、正しい人に、正しいタイミングで届ける」という原則への回帰とも言えます。
AIという強力な技術の登場は、この原則の重要性を改めて浮き彫りにしました。データの品質、ガバナンス、アクセシビリティといった基本的な要素が整っていない状態でAIを導入しても、期待する成果は得られません。冒頭で述べたAIプロジェクトの高い失敗率は、この基本を軽視した結果とも言えるでしょう。
真の「AI Ready」とは、最新のツールを導入することではなく、ビジネス課題を起点にデータ戦略を組み立て、それを支える堅牢なデータマネジメント体制を構築することです。技術の進化は目まぐるしいものですが、データマネジメントの原理原則は不変です。その原則に立ち返り、自社のデータ資産を戦略的に管理することが、AI時代における競争優位性の源泉となるのです。
そして、この取り組みは一度きりのプロジェクトではなく、継続的な改善を要する組織的な営みです。ビジネス環境が変化し、解決すべき課題が進化する中で、データマネジメントもまた進化し続ける必要があります。その中心には常に「どのビジネス課題を解決するか」という問いがあるべきなのです。

弥生 隆明 (やよい たかあき)
データブリックス・ジャパン株式会社
フィールドエンジニアリング本部
筑波大学大学院を修了後、株式会社IHIに入社。社内システム部門でサーバー・ネットワーク管理やシステム開発に従事。その後、株式会社日立製作所において自然言語処理に関する研究開発やITコンサルティング、インターネットサービスの開発・運用、インド赴任を通じてビッグデータソリューション創出に従事。その後、アクセンチュア株式会社にてデータ分析プロジェクトに従事。現在、Databricks Japanにてシニア・スペシャリスト・ソリューションアーキテクトとして、生成AIやデータエンジニアリングを専門として企業へのレイクハウス・データ分析ソリューションの導入支援などに従事。主な著書は「Apache Spark徹底入門」など。
Databricks HP https://www.databricks.com/jp
Databricks Unity Catalog https://www.databricks.com/jp/product/unity-catalog
Qiita https://qiita.com/taka_yayoi