
MDMとデータガバナンス研究会リーダー 水谷 哲
2021年1月28日、「MDMとデータガバナンス研究会#8」は「日本のデータガバナンスとこれから」をテーマに開催された。ゲスト講師として登壇したのは、データカタログのサービスを立ち上げたスタートアップ企業、Quollio Technologies(以下、クオリオ) 代表取締役の松元亮太氏。同社が提供する「クオリオデータカタログ」とはどんなサービスなのか。サービスの概要に加えデータカタログ・データガバナンスの重要性、世界のデータ基盤の潮流などが紹介された。
■組織のメタデータ管理を最適化するSaaS「クオリオデータカタログ」とは

創業者3氏。右から、春田拓海氏(取締役 CTO)、松元亮太氏(代表取締役 CEO)、眞田貴央氏(取締役 Head of R&D)
クオリオは2021年8月に設立されたITスタートアップ。1月11日にインキュベイトファンドから5000万円の資金調達を実施し、企業のデータガバナンスを実現するクオリオデータカタログの開発を推進しており、2月1日にα版を提供開始した。α版ではデータウエアハウスからデータ概要を自動取得と辞書生成、およびブラウザ上でメタデータの一元管理が可能になるという。なぜ、松元氏はクオリオを起業し、データカタログの開発・提供に取り組むことになったのか。松元氏の発表を以下に紹介する。
当社のミッションは、「世界中の情報と知を繋げ、人類の新たな価値創造を促進する」ことです。創業して間もないですが、VCからの資金調達も実施し、上場を目指してプロダクトの開発に従事しています。
私を含めた創業者の3人は、いずれもデータサイエンティストやデータエンジニアのバックグラウンドがあります。私自身、クオリオは2社目の創業。最初にやっていた会社を辞め、監査法人でデータサイエンティストに従事。その後、クオリオを創業して、クオリオデータカタログというSaaSを開発しています。
クオリオデータカタログは、組織のメタデータ管理を最適化する大企業向けのSaaSサービスです。重要なデータの自動検知を行い、データ活用をセキュアに保つというコンセプトを持っています。もちろん日本語対応済みです。
皆様ご存じとは思いますが、メタデータは色々なことに役立ちます。例えばデータガバナンス、コンプライアンス、アクセスコントロール、そしてデータ利活用のためのデータ品質の担保などに活用できます。
データ活用の現場において、次のような課題を抱えていることが多いのではないでしょうか。
1. データ定義に関するドキュメント作りに手間がかかる
データ定義書をExcelでアドホックに色々と作ったり、Confluenceというサービスでデータ定義を管理したりする場合、企業のデータが増えたり、消えたり、複製されたり、移動したりする際、定義書の方の更新が滞ったり、あるいは場所が分からなくなったりします。
2. データ作成者と利用者の間で情報共有ができない
データエンジニアなどのデータ作成者と、アナリストなど利用者との間で情報共有が十分に行えず、データ作成者の意図を利用者が正確に把握できていないことがよくあります。さらに、部署異動や入退職が行われる過程で、データに関する知識が失われていきます。
3. 隠れた重要データの存在を把握し切れていない
個人情報などの「センシティブデータ」と言われる、会社にとって重要なデータが散在しており、誰がどこで使っているのか把握し切れていない。誤って使用されていないかのリスクがある。
これらの課題をクオリオデータカタログなら解決できます。
(1)クオリオデータカタログは、データ概要を自動取得し、辞書を生成します。今までExcelやConfluenceではできなかった自動的なデータの更新検知によって、理想的なデータ定義書の運営を可能とし、データエンジニアの工数を大幅に削減します。
(2)クオリオデータカタログはデータに対する背景情報、いわゆるデータ資産のあらゆるメタデータをSaaS上で一元管理し、メタデータを社内の誰もが参照できる状態に保持します。
(3)個人情報をはじめとするセンシティブデータなどの重要データを自動的に検出。隠れた重要データの誤用を防ぎます。
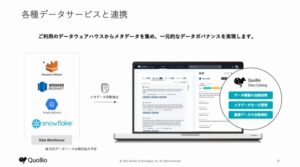
具体的な使い方は、次の図をご参照下さい。各種データサービス、例えばAmazon AthenaやAmazon Redshift、Google BigQuery、Snowflakeなどクラウドネイティブなデータウエアハウスからメタデータを自動抽出し、データカタログとして管理することで、一元的なデータガバナンスを実現します。
■ソリューションに対して活発な質疑応答が行われた
ここでサービスの紹介は終了。質疑応答タイムへと入った。
水谷:クオリオデータカタログのコンセプトへの質問、日頃の疑問などあればお願いします。
伊阪:このサービスではリポジトリの概念を取り込んでいないのでしょうか。
水谷:質問の補足です。カタログ自体がデータリポジトリと言えるわけですが、例えばConfluenceなどからデータをインポートする機能を備えているのでしょうか。
松元:ExcelやConfluenceなどで管理しているビジネスメタデータ(データの入手背景や禁止事項などの詳細情報)を、表形式で取り込むことができます。
伊阪:ここで使われている「ビジネス」という用語は業務の意味だと思います。日本では、業務データと呼ぶほうが、誤解が生じないのではと思いました。リポジトリはExcel以前の1970年代からあり、大手企業ではリポジトリを作成し、データスチュワードがしっかり管理しています。データカタログは非常によい概念ですが、Excel以上の機能は不要だという企業が多いのではと思いました。
真野:システムメタデータは自動的に吸い上げて、ビジネス・グロッサリーはExcelで定義した情報を取り込むと理解しました。クオリオデータカタログ自身の持つメタ構造の基本的な構成について教えてください。ビジネス・グロッサリーにおいては、ビジネスメタデータの構造を予め定義しておき、それに従って用語を登録するイメージのものが多い。ビジネス・グロッサリーをどういう風に作っていくかというところに頭を悩ませている人が多い。
松元:おっしゃるとおり、システムメタデータはデータベースから直接拾ってきて、ビジネス・グロッサリーは、ExcelやConfluenceから取り込めます。クオリオではビジネス・グロッサリー上にタグを生成して、そのタグをデータセットに対して付与できるというタグ登録の仕組みがあります。そのタグ登録のルールもクオリオで管理できるようになっています。
真野:最も必要なのは、ビジネスメタデータとシステムメタデータをマッピングして見せること。業務ユーザーにとって、自分の欲しいデータがどこかにあるのかが、データカタログで見えるといいなと思いました。
春田:クオリオデータカタログはデータウエアハウスやデータレイクに入っているデータに対して、WebのUIで情報系や品質系の情報を付与し管理しやすくしています。またルールという一定の規則に従ってデータにタグやメタデータを付与することで管理を楽にします。データカタログの中身については、基本的に各DWHから共通の項目を取得します。クオリオデータカタログはデータ基盤が出来上がった後で活用するツールです。
真野:実装されたDBMSのカタログやコメント情報以外に、例えばセキュリティの情報などのタグや説明を付加したり、グルーピングしたりする感じでしょうか。
春田:基幹システムのRDBから情報を取得するのは、まだ先の予定です。現在のターゲットはクラウドのDWHです。それらのデータに対してカタログを作り、タグを付与していきます。
真野:実装されたDBMSの情報を直接見ても、ユーザーにとってなかなか解りづらいのではと思います。
春田:企業が悩んでいるポイント、例えば個人情報に関する項目にテンプレートを用意することなども考えています。データマネジメントにおいて重要なのは、データの所有者が誰でデータ品質はどうなのかというところです。クオリオデータカタログではDWHにアクセスする際に解析を行い、ルールに従ってテーブルやカラムに対してタグを自動で付与するという運用を想定しています。
小川:ルールに基づいてタグ付けしていく機能をメインとして、中でもセキュリティの観点から、個人情報や万人に見せてはいけない情報などを素早く検知することが目的と思いましたが、合っていますでしょうか。
松元:そうです。
小川:例えばこのデータとこのデータはセットで管理するというタグ付けもできたりするのでしょうか。
松元:そういうこともカバーできると思います。
和田:大企業向けのサービスとのことでしたが、大企業のどこの部署に踏み込んでいらっしゃいますか。
松元:Amazon AthenaやAmazon Redshift、Google BigQuery、SnowflakeなどのクラウドネイティブなDWHを活用して、データ分析基盤のパイプラインを構築しているエンジニアのいる部署がターゲットです。
水谷:データカタログというと、たとえばApache Atlasとクオリオデータカタログはどう違うのか、競合しているのかを教えてください。
松元:確かに欧米ではApache Atlasをはじめ、データカタログのツールは複数存在していて、すでに色々なユースケースが登場しています。クオリオデータカタログもApache Atlasも概念的には似ていますが、Apache Atlasがあれば、クオリオデータカタログが不要というわけではありません。もしもApache Atlasでメタデータ管理を行っており、運用保守もうまく回っているのであれば、当社のサービスは不要かもしれません。ですが、ビジネスメタデータやビジネス・グロッサリーの管理、維持管理に関わるコミュニケーションなどに課題が出てくると思われます。そこで当社のサービスを有効に活用できると思います。
水谷:データレイクは毎日あるいは毎時間ごとにCSVファイルがどんどん追加されていくことがあります。例えば「1月27日ファイル」と同じところに「1月28日ファイル」が作成されたような場合、自動的にその項目を吸い上げてデータカタログで見せるようなことまでできるようになったりするのでしょうか。
松元:今のところは別ファイルとして認識されるという理解になります。直近ではあまり考えていません。
春田:前職のクラスメソッドでAWSを活用したデータ分析基盤を構築していた経験から言うと、例えばAmazon S3のAIを活用したデータセキュリティサービスを活用したり、S3インベントリの機能を使ったりすることで技術的には可能です。しかし色々なパターンのものがあるので、網羅的に追従するのはかなり難しいと思います。ある程度規則的なものに対して、今後のロードマップで採用していく形になります。
吉村:クオリオデータカタログの一番の「売り」を教えてください。例えばDWHにメタデータを付与していくところが効率化される、もしくは人海戦術でやっていると限界があるような部分を半自動化されるなどは、他のデータカタログ製品でも同様のことを謳っていたりすると思います。
松元:海外製品の場合、自動化に力を入れているモノが多いと感じています。例えば「これは98%の確立で電話番号ですよ」というように。しかし、たとえば「80%の確率で電話番号」と言われたときに、残りの20%は何だろうと思うわけです。結局は人が見に行ってその20%を探索し、100%の確認をしないといけません。海外製品の場合は80%を導くロジックがブラックボックスで、単なるサジェスチョンでしかならない状態が起こっているんです。我々のデータカタログでは、データの自動付与をホワイトボックス化することを基本としています。つまり、「こういうロジックで自動タグ付けしている」ことを常にわかるように作っています。だからこそ、ルールをセルフで作れる機能を重視しています。
小関:ルールをホワイトボックス化したところに、AIを使ったルールを組み込むのが難しそうに感じました。AIを使った自動判別や機械判別は、最終的に中身はブラックボックスとなります。精度は90%だけど中身はブラックボックス、精度は70%だけど中身はホワイトボックスというものがあって、現状ではどちらがよいか判断がつかないような気がします。この辺はあくまでも使い分けていくと言うことでしょうか。
松元:最初はルールベースでホワイトボックス化された自動化のタグ付けを行い、その次の段階としてマシンラーニングをアドバンストフィーチャーというかたちで付け加えていくことを考えています。70%で透明性があるものと90%でブラックボックスとどちらを重視するかというと、前者の透明性を当社は重視するという考え方です。
水谷:データカタログ論の議論については、別途機会を設けたいと思います。クオリオデータカタログと、DAMA-DMBOKとでは、「データカタログ」の違いはありますか。
春田: DAMAが論じてきたDMBOKにおけるデータガバナンスやデータマネジメントは非常に重要だと思いますが、弊社は「今のUS市場でめちゃくちゃホットになっているデータカタログ」を日本で再現するというビジョンで開発を進めています。今回の参加している会社の中で、どのくらいがデータカタログを使っているのでしょうか。
徳山:2~3社でPoCを実施しました。よくも悪くも、大して評価できずに過ぎていくというケースが多かったですね。期待が大きすぎたのだと思います。いろんな要望を1つに絞り、ちゃんと使えるデータカタログがあると、ユーザーにとってフィットし、そこから広がるのではと思いました。
真野:この業種・業務に強い、またはフォーカスしている業種・業務があれば教えてください。
松元:Webサービスやゲームなど、プロダクトを持っている会社での導入が多いですね。ユーザーの行動データを分析するデータ活用基盤を構築している、セールスとマーケティングを統合して分析したいという企業に対してアプローチしています。
■世界のデータ基盤の潮流「モダンデータスタック」とは
ここでサービスに対する質疑応答は一旦終了。第2章として世界のデータ基盤の動向について松元氏の発表が始まった。
現在、海外ではモダンデータスタックが非常に流行しているという。解説を進める前に、松元氏は参加者に「モダンデータスタックという言葉を耳にしたことがあるかどうか」を質問。ワコムの深井氏が「まったく知らない」と回答したように、多くの参加者にとってはあまり耳なじみのない言葉だったようだ。モダンデータスタックとは何か。松元氏の発表を以下に紹介する。
モダンデータスタックという概念が提唱され始めたのは今から3~4年前。日本語にするとモダンな(もしくは現代の)データ基盤という概念が、世界中で流行を見せています。10年代にDMBOKが普及して以降、データマネジメントに関するさまざまな議論が行われ、検証されてきました。その中にはデータガバナンスやデータカタログというキーワードがあります。昨今、このモダンデータスタックというデータ基盤の構成が流行り始めたことによって、データガバナンスやデータカタログの定義が変わったこともあり、新たにスポットが当たりつつあります。
モダンデータスタックは次のようなソリューションで構成されます。

図の出典先 https://snowplowanalytics.com/blog/2021/05/12/modern-data-stack/
データマネジメントレイヤーとして、Alation、Alex、Collibra、Amundsenなどのデータカタログ/ガバナンスのソリューションが登場し、注目を集めています。
モダンデータスタックは基本的にマルチクラウドが前提です。
世界のデータ基盤の歴史を振り返ると、第1世代のデータ基盤の特徴は「オンプレミスとサイロ化」。Redshift登場以降、第2世代が始まりました。その特徴は「クラウド化とデータレイク、DWHによる一元的アーキテクチャ」です。ここからがモダンデータスタックの始まり。最近はさらに発展して、「データを1つのDWHに蓄積して活用するのではなく、ストレージ、パイプライン、データカタログ、アクセスコントロールで構成されるCommon Data Infra(コモンデータインフラ)」の時代に(第3世代)。Common Data InfraはData as a Product、データメッシュという特徴を持っています。第3世代のモダンデータスタックはマルチクラウドが前提となっているため、一つのサービスにロックインされることはありません。つまりSnowflakeやRedshift、Google Big Queryなどもデータカタログ/データガバナンス機能を持っていますが、マルチクラウドを前提とするためには、それらを表面上で一つに統合して全体を管理できるツールが必要になります。そのためデータカタログやデータガバナンスが再定義されるようになっているのです。
米国の企業は、この第3世代のモダンデータスタックを起点にデータ分析基盤の構築を考えるようになっています。製品開発もモダンデータスタックを基本に行われています。
このUSの考えをそのまま日本に適用していくことは難しいのが現状です。そこに当社の役割があります。いかに日本にモダンデータスタックという考え方を普及させていくかという話だけではなく、そもそもモダンデータスタックのような仕組みが必要なのかということから、これから議論していかなければならないと思います。そうした状況に対して、データカタログやデータガバナンスはどうあるべきかを考えていく。日本ではまだそういう状況なので、私たちのような専業ベンダーがいることが大事だと考えています。当社はソフトウェアとテクノロジーの力を用いて、組織のデータガバナンスを活性化させることで、企業がデータから新しい価値を創出することを促進させたいと考えています。ですが、この分野を活性化させるには、私たち以外にもプレイヤーが増えることも望んでいます。
■日本のデータ基盤は第1世代か、進んでいても第2世代?
2回目のQ&Aタイムが始まった。
尾関:先のモダンデータスタックの図は、日本ではメジャーではない製品が含まれているので、日本のマーケットですでに普及している製品で図を再構成すると、啓蒙が早いように感じます。日本では半歩先を見せることが重要なので、このままだとモダンデータスタックは画期的ですが、日本のお客さまはなかなか付いていけないような気がします。
水谷:「オペレーション」領域以外は、ジャンルとしては成立しています。ジャンル毎に、分かる人が見れば解るのですが、プロダクト単体ごとに見ると知名度が低いものがたくさんあるように思います。
春田:日本的な大企業もクラウド移行へと動き出しています。当社のソリューションも当面やAWSやGCP、Azureを補完するソリューションとして配置してもらうことを考えています。
深井:非常に尖っているなと思いました。中世の日本に南蛮渡来のキリスト教を布教するような志の高さを感じました。
松元:ありがとうございます。
佐野:日本はまだ第1世代か第2世代に行っているか、行っていないかのレベルだと思います。例えばそのようなレベルの企業でもこのソリューションはうまく活用できるのでしょうか。
松元:クラウドにまったくデータが上がっていない、データ活用基盤がないという企業は、データカタログを導入する段階ではないと考えています。
佐野:データ活用にはデータのクレンジングが必要だと考えているが、それをやってからでないと活用できないのでしょうか。
松元:データカタログも魔法のツールではないので、データをクレンジングすることはできません。データレイクアーキテクチャにデータを集めて、加工して活用するというタイプの企業であれば、どのデータをクレンジングした方がよいかという判断は付くのではないでしょうか。
水谷:データスチュワードを用意してから、ということですね。
佐野:ソリューションを導入する際は、状況把握から手がけていかれるのでしょうか。
春田:弊社としてはSI的な動きをすることは考えていません。大手SIerと協業していく予定です。
水谷:メタデータ管理手法として、5年前の構想ではありますがメタデータ管理の壮大な構想の翻訳が完了し、JDMCで公開する予定です。これに目を通すとデータカタログ全体像への理解を進めることができそうな資料なので、公開されたらぜひ読んでください。
日本ではまだ基幹系システムのデータは整備されていませんが、Web経由のデータはそれなりに整っています。こちらの方面からデータカタログは日本でも花開くのではないかと思いました。今日はありがとうございました。
<関連サイト>
Quollio Technologies ホームページ
https://quollio.com/
Quollio Technologies プレスリリース
https://prtimes.jp/main/html/rd/p/000000002.000090718.html